自定义深度学习分类
该功能采用深度学习算法对点云或影像数据进行分类。此功能采用监督分类,在同一批次数据中,需要手工编辑少量数据的类别,训练模型后批量处理大量数据。支持两种流程:选择训练样本,生成训练模型,处理待分类数据,利用已有的模型处理待分类数据。
使用此功能请确保您已经安装深度学习服务
要求
| GPU 要求 | 描述 |
|---|---|
| GPU 类型 | CUDA 计算能力最小 3.5, 推荐6.1或更高. 查阅更多资料 Compute Capability |
| GPU 内存 | 推荐: 8GB 或更高, 取决于深度学习模型结构和批次大小 |
用法
点击 分类 >自定义深度学习分类
使用流程:数据准备-->训练点云分类模型-->使用训练模型分类
如下为任务管理页面,可显示状态/管理训练点云分类模型任务,使用训练模型分类任务.
工具栏从左往右依次为 新建任务,删除任务,启动任务,暂停任务,导出任务,任务信息,导入任务,模型管理,刷新
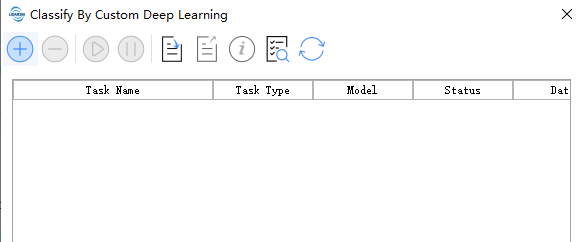
任务管理页面,可显示状态/管理训练点云分类模型任务。
数据准备
点云
在训练之前应当准备好训练需要的数据(已标记数据),可使用LiDAR360提供的剖面编辑功能编辑类别数据。训练数据应为真实场景数据,允许使用LAS,LAZ,LiData三种格式的数据。根据场景和算法的处理方式不同来调整训练数据数量。原则上参与训练的标注数据越多越好,我们推荐至少准备100m*100m范围的数据使用,以获取良好的使用体验。请注意,数据的标注一定要统一原则,类别的设定尽量不要根据场景变动。错误的标注数据将会带来负面的影响。
影像
在训练之前应当准备好训练需要的数据(已标记数据),可使用LiDAR360提供的SAM矢量编辑导出labelme标注功能,或者使用直接labelme工具进行标注。训练数据应为真实场景数据,允许使用常见的jpg,png,tif等影像格式。每张影像建议尺寸小于2048*2048,否则图像太大将导致训练效果很差。大图像建议切图后再进行标注。
训练模型
点云
点击 分类>深度学习自动分类->训练点云模型
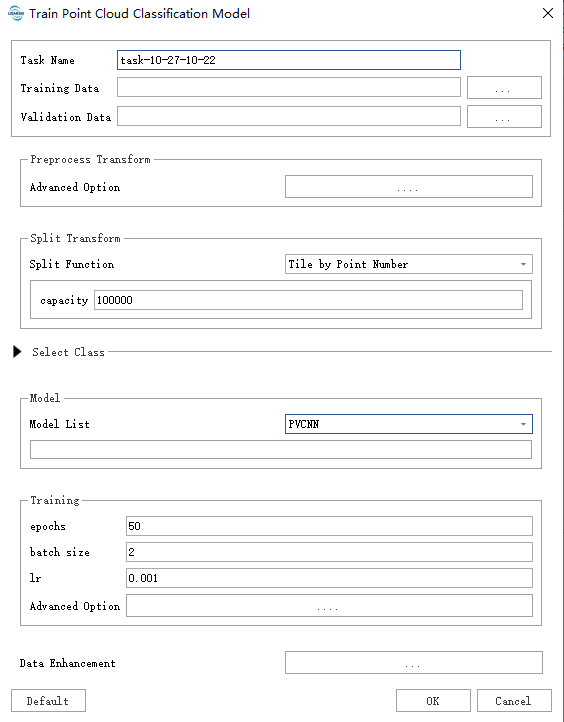
用户在按需填写数据路径后,点击default使用默认参数即可开始使用。
- Task Name: 任务名将作为训练好的模型名称。
- Training Data: 将已做好类别标记的数据放在同一文件夹下,会读取文件夹下支持的数据格式所有数据。
- Validation Data:将已做好类别标记的数据放在同一文件夹下,此文件夹下数据将作为范本计算准确率等指标。
数据预处理:
- Advanced Option:可在此处选择数据预处理函数,通常有统计滤波,体素滤波等,一般为避免过密的数据引起意外内存不足问题默认使用体素滤波。
分块函数:
- Split Function: 数据分割,为了避免使用过多的显存,建议用户将数据分割到合适的大小,分割的尺寸选择与数据分布,算法等有关。参数填写指南。
选择类别: 类别映射,其中Sample Class为训练样本的类别,Merge Tags为将对应Sample Class中的类别合并为一个类别进行训练,Sample Class一或多对应Merge Tags,需注意Sample Class设置时应该包含训练样本数据中所有的类别,Merge Tags中0对应的类别为背景不参与训练。
模型:
- Model List: 模型暂提供SPVANS,DRINet,PVCNN,KPConv,MinkUNet五个经典模型(非原版实现,有少量变更),针对这五个算法我们都有提供对应的推荐参数设置,推荐使用左下角Default按钮自动填写后续参数。
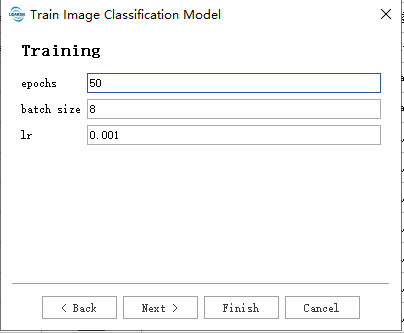
训练:
- epochs 迭代周期,每次完整循环处理完所有数据为一个epochs。
- batch size:每批量数据,即每次模型处理几个数据,在内存允许的状态下一般越大越好,在模型精度与训练速度上更有优势.对于具有 8 GB 专用 RAM 的 GPU,请使用默认的批量大小 2,如果您发现训练期间仍有大量 GPU 内存可用,则可以安全地增加批量大小,以一次处理更多块。
- lr:learning rate 学习率,配合优化器控制模型学习的速度与方向(通常学习率越低越稳定也更容易陷入鞍点)。
- optimizer:优化器,同上。
- lr scheduler:学习率控制器,随周期变化的学习率在某些情况下能获取更好的精度。
- loss:损失函数,在Advanced Option中,默认使用交叉熵CrossEntropyLoss ,FocalLoss一般来说在类别不均衡时有更佳的效果在标签有误的情况下效果可能更差,推荐使用交叉熵。
上述加粗为必填参数,其他可选填。值得注意的是随着版本的更迭,参数可能会出现变动。
影像
点击 分类>深度学习自动分类->训练点云分类模型
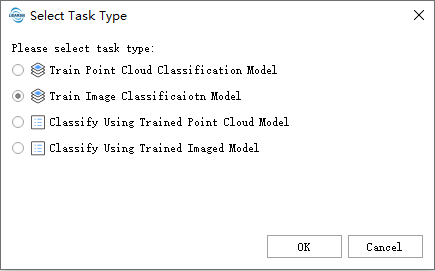
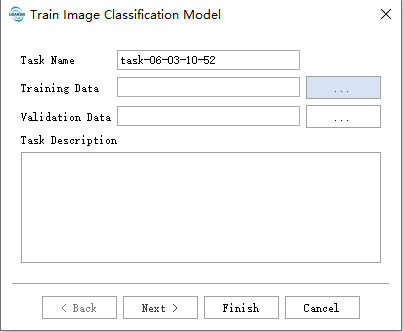
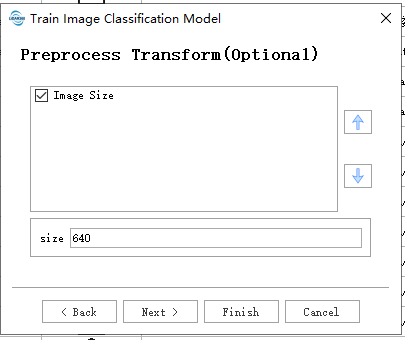
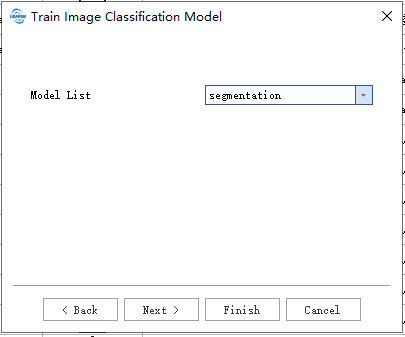
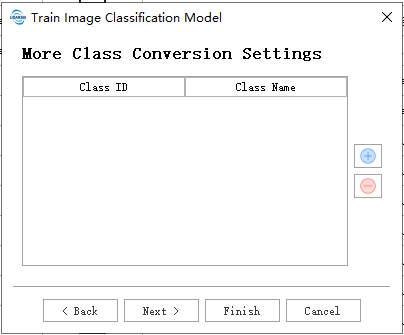
用户在按需填写数据路径后,点击default使用默认参数即可开始使用。
- Task Name:任务名将作为训练好的模型名称。
- Training Data:将已做好类别标记的数据和标注文件放在同一文件夹下,会读取文件夹下支持的数据格式的所有文件以及对应标注文件。图像和标注文件格式如下图所示

Validation Data:将已做好类别标记的数据和标注文件放在同一文件夹下,图像和标注文件格式如Training Data中一致,此文件夹下数据将作为范本计算准确率等指标。
数据预处理:
- Image Size:训练图像的大小,训练时候图像将会被调整为设置的大小。
- 选择类别:类别映射,标注的标签数值类别与真实类别。
- 模型:
- Model List: 模型暂提供segmentation,detection两种。segmentation是进行图像分割任务,detection是进行图像目标检测任务。
训练:
- epochs:迭代周期,每次完整循环处理完所有数据为一个epochs。
- batch size:每批量数据,即每次模型处理几个数据,在内存允许的状态下一般越大越好,在模型精度与训练速度上更有优势.对于具有 8 GB 专用 RAM 的 GPU,请使用默认的批量大小 2,如果您发现训练期间仍有大量 GPU 内存可用,则可以安全地增加批量大小,以一次处理更多块。
- lr:learning rate 学习率,配合优化器控制模型学习的速度与方向(通常学习率越低越稳定也更容易陷入鞍点)。
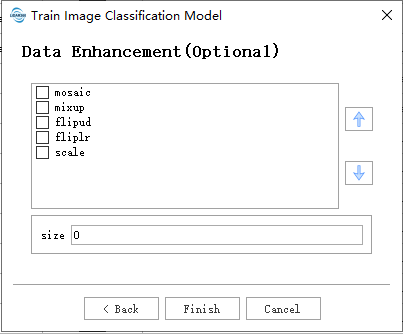
数据增强:
mosaic:将四幅训练图像合成一幅,模拟不同的场景构成和物体互动。对复杂场景的理解非常有效。
mixup:混合两幅图像及其标签,创建合成图像。通过引入标签噪声和视觉变化,增强模型的泛化能力。
flipud:以指定的概率将图像翻转过来,在不影响物体特征的情况下增加数据的可变性。
- fliplr:以指定的概率将图像从左到右翻转,这对学习对称物体和增加数据集多样性非常有用
- scale:通过增益因子缩放图像,模拟物体与摄像机的不同距离。
上述加粗为必填参数,其他可选填。值得注意的是随着版本的更迭,参数可能会出现变动。
>
使用训练模型
点云
点击 分类 >深度学习自动分类 >使用训练模型分类
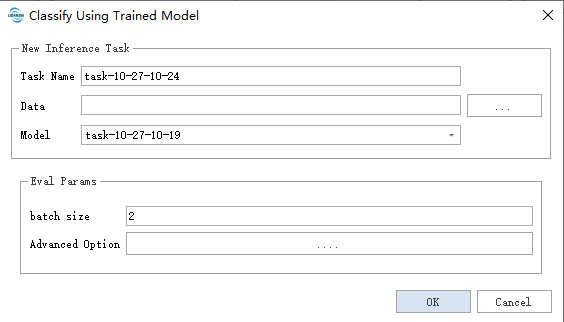
- Data :会读取文件夹下支持的数据格式所有数据,并直接修改源数据,在需要时请自行备份数据。
- Model :选择使用的模型,其中Model的名称将以训练任务名命名,在训练完成后将自动添加进入Model管理。
评估参数:
- batch size:主要控制每次进入模型的数据量,适量增大可加快速度同时会带来更多的内存占用
- weight name:控制选择某项最佳指标(如acc miou等)模型
模型将会在训练任务完全停止时产生(训练任务完成,训练任务暂停,训练任务由内存超出退出)。
上述加粗必填参数,其他可选填。
值得注意的是随着版本的更迭,参数可能会出现变动。
影像
点击 分类 >深度学习自动分类 >使用影像模型
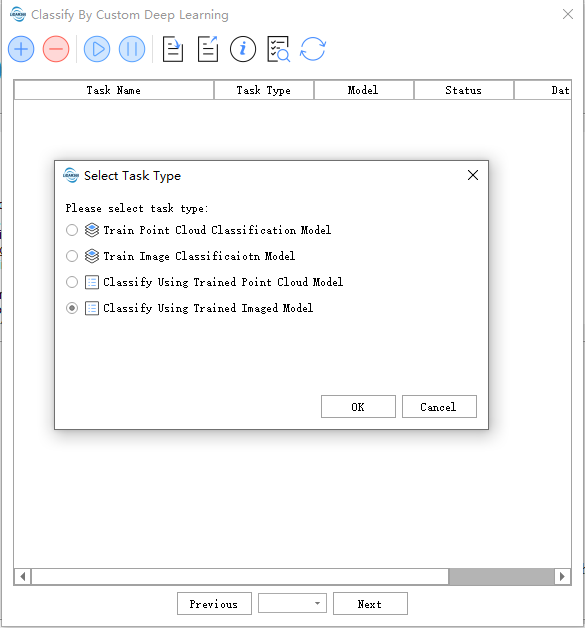
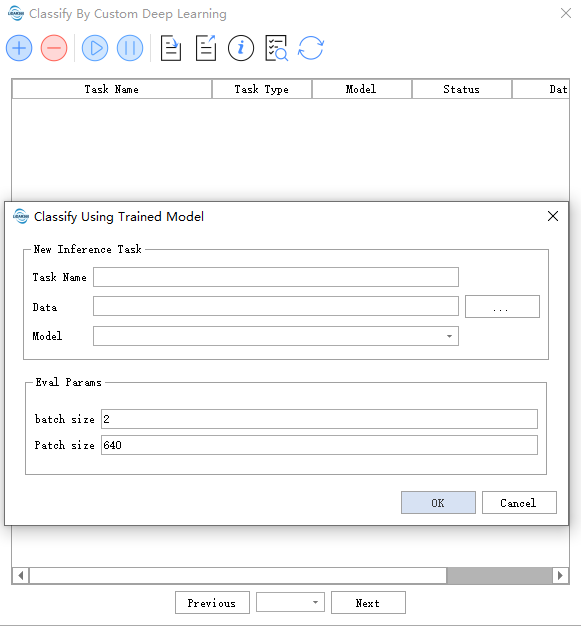
- Data: 会读取文件夹下支持的数据格式所有数据。
- Model :选择使用的模型,其中Model的名称将以训练任务名命名,在训练完成后将自动添加进入Model管理。
评估参数:
- batch size:主要控制每次进入模型的数据量,适量增大可加快速度同时会带来更多的内存占用
- Patch size:推理模型时候图像分块的大小
模型将会在训练任务完全停止时产生(训练任务完成,训练任务暂停,训练任务由内存超出退出)。
上述加粗必填参数,其他可选填。
值得注意的是随着版本的更迭,参数可能会出现变动。
评估训练结果
点云:
提供三个指标MIoU,Acc,MAcc,主要基于混淆矩阵计算
真实值positive,模型认为是positive的数量(True Positive=TP) 真实值positive,模型认为是negative的数量(False Negative=FN) 真实值negative,模型认为是positive的数量(False Positive=FP) 真实值negative,模型认为是negative的数量(True Negative=TN)
| 真实类别 | |||
| 1 | 0 | ||
| 预测类别 | 1 Positive |
True Positive 真阳 |
False Positive 伪阳 |
| 0 Negative |
False Negative 伪阴 |
True Negative 真阴 |
|
这样的四个指标组成的表格成为混淆矩阵
IoU(Intersection over Union) 交并比
即目标与预测的交集/目标与预测的并集
MIoU(Mean Intersection over Union) 平均交并比
Acc(Accuracy)
召回率(recall)
平均精度(AP):PR曲线以下与横轴、纵轴之间的面积。PR曲线是由Precision(精准率或者查准率)与Recall(召回率或者查全率)构成的曲线,横轴为Recall,纵轴为Precision
均值平均精度(mAP):所有类别的平均精度求和除以所有类别
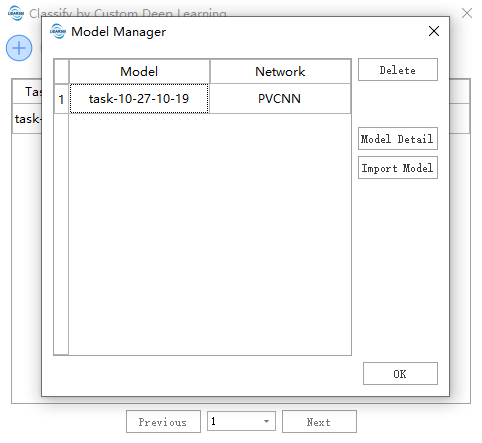
模型管理
模型管理界面可管理可用模型,也可以导入外部模型(仅限LiDAR360客户端产出模型)。
导入任务
可导入外部模型,获取参数/权重。
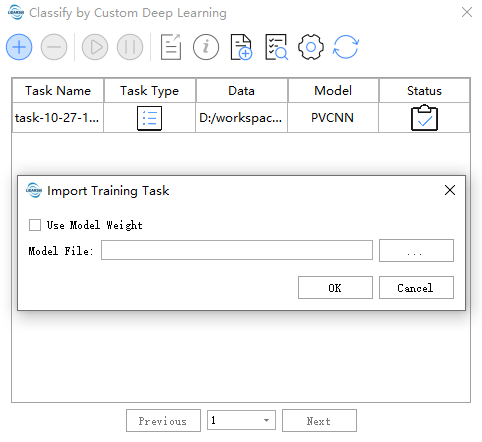
模型文件:外部模型文件路径(仅支持LiDAR360客户端产出)。
Use Model Weight:模型权重,勾选时为继续训练,不勾选时仅获取模型训练参数。
深度学习模型对比
点云
以下数据为训练阶段,使用voxel size为0.5的体素下采样,单个数据约20w点,批次为2统计。时间复杂度与空间复杂度主要受数据疏密程度影响,模型多次下采样后的点密度难以控制,只能给到一个大概值提供参考。
硬件配置
CPU:i7-10700k(8t16c)
GPU:RTX3060
| 算法 | 速度(items/s) | 内存占用(GB) |
|---|---|---|
| PVCNN | 1.82 | 8G |
| KPConv | 0.04 | 11G |
| MinkUNet | 1.05 | 8G |
通常来说KPConv拥有最高的精度与细节表现,推荐在需要精细分类的小场景下使用此模型。MinkUNet有更大的视野与合适的速度,推荐在大场景下使用。PVCNN拥有不错的细节表现和最快的速度,一般情况下都推荐使用此模型。
影像
以下数据为训练阶段,批次为4统计。
| 速度(items/s) | 内存占用(GB) | |
|---|---|---|
| segmentation | 3 | 2G |
| detection | 3 | 2G |
特征选择
点云
根据数据特定可以添加RGB与Intensity特征。RGB与Intensity特征可以使模型更早的拟合,在最终精度方面差别不大(视实际数据情况),在内存占用与计算速度上的差异可忽略不计。
| 特征 | miou |
|---|---|
| RGB+Intensity | 99.1 |
| Intensity | 98.8 |
| RGB | 99.0 |
| 无 | 98.7 |
影像
无需选择特征
数据分割
点云
一般建议用户最少选择欲分类个体类别最大尺寸(如欲分类建筑物个体最大为80m*80m,建议分块使用Tile by Range 参数length为90或以上),再根据硬件状况酌情增加。 Tile by Range Point Number 按点数分割,在数据不均匀分布时(如稀疏场景下)可能带来更好的性能。
影像
一般建议用户在进行训练时候对数据进行分块处理,分块大小建议不超过2048。
调试指南
- 内存不够:调小batch_size参数,点云可以调小split transform分割大小,影像可以调小Image Size。
- 类别不均衡:推荐loss更改为Focal Loss。
- loss来回跳动:训练初期时可多等待训练几轮,如果在10-20epoch还不能稳定,可尝试调小lr/10,推荐在lr_scheduler使用Cosine Annealing WarmRestarts。如有需要可前期使用大lr训练,后期使用导入模型训练功能更改为小lr继续训练。
注意事项
- 验证集默认使用训练集的数据增强。
- 用户如未指定输入特征,将根据模型需要输入基础特征。